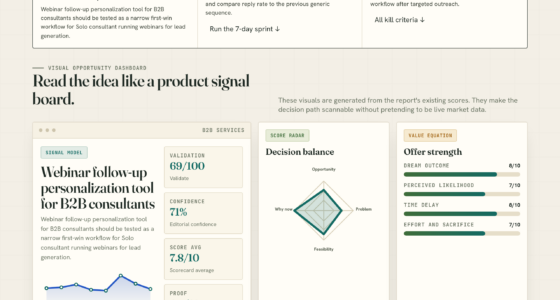
📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
AI industry is shifting from renting compute to securing exclusive data sources. Confirmed: data scarcity is now the primary chokepoint, with legal and strategic fencing intensifying. Uncertain: future access models and how startups will compete.
Data has become the new chokepoint in AI development, as industry leaders acknowledge that the era of freely scraping the web for training data is over. Confirmed by recent legal settlements and market shifts, access to verified, proprietary data now determines competitive advantage in AI research and deployment.
Recent legal actions, including Anthropic’s $1.5 billion settlement over copyright claims and ongoing lawsuits involving major publishers like The New York Times, confirm that the industry is moving away from free data scraping toward a market-based licensing regime. This shift effectively fences off large swaths of valuable data, making it a costly resource that favors well-funded incumbents.
Simultaneously, the industry is witnessing a transformation in data requirements. As AI models advance from simple classification to complex reasoning, they depend increasingly on high-cost, expert-labeled data generated by rare professionals—lawyers, scientists, and domain specialists—rather than low-cost crowd-sourced labels. This evolution has turned data access into a strategic asset, with companies vying for exclusive rights to unique datasets.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Why Data Scarcity Reshapes AI Industry Power
The increasing fencing and monetization of data create high barriers to entry for startups and emerging players, consolidating power among large incumbents with deep pockets. This trend may limit innovation by making access to high-quality, verified data prohibitively expensive for smaller firms, thus impacting the overall diversity and progress of AI development.
Moreover, as data becomes a national and strategic asset, governments and corporations are likely to treat access as a matter of national security, further complicating open research and collaboration. The industry’s shift toward proprietary datasets marks a fundamental change in how AI models are trained and who controls the knowledge base behind them.

Understanding Open Source and Free Software Licensing
Used Book in Good Condition
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Market Shifts in Data Access Since 2025
In 2025, landmark legal cases such as Anthropic’s copyright settlement signaled the end of the era of free, unlicensed web scraping for training data. Major publishers and authors have moved from litigation to licensing, establishing market-based pricing for data use. This has led to a significant increase in data costs, with some estimates indicating licensing fees reaching billions of dollars for large datasets.
At the same time, the industry is experiencing a shift toward sourcing data from proprietary, high-value domains—paywalled content, enterprise data, and expert-generated annotations—further restricting access and increasing reliance on exclusive partnerships. This trend is reinforced by strategic moves like Meta’s investment in expert data firms and the exit of vendors dependent on a few major clients, exemplified by the decline of Appen.
“The era of free scraping is over, and a market-based licensing regime for training data is forming in its place.”
— Thorsten Meyer
expert-labeled data sets for AI
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unclear Future of Data Access and Industry Impact
It remains uncertain how startups and smaller labs will adapt to the high costs and legal restrictions now governing data access. Will new models of data sharing emerge, or will proprietary datasets dominate AI development? The long-term effects on innovation and competition are still emerging and debated.
proprietary data collection tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in Data Market Evolution and Industry Strategies
Industry players are likely to pursue more exclusive data partnerships, develop synthetic and verified datasets, and lobby for legal frameworks that protect proprietary data. Monitoring legal rulings, licensing agreements, and new data sourcing strategies will be crucial as the industry navigates this new landscape.

The Remote AI Training and Data Annotation Handbook: A Complete Work Resource Guide for Earning Online Through Microtasking Platforms
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why can’t data be rented like compute resources?
Unlike compute or power, data is a finite resource that often requires verification, licensing, and legal clearance. Its uniqueness and value—especially proprietary, verified data—make it inherently non-rentable and highly guarded.
How does legal action affect data availability?
Legal rulings, such as copyright settlements and court decisions, are increasingly restricting free data scraping and pushing the industry toward paid licensing, thus fencing off large data sources.
What does this mean for AI startups?
High licensing costs and restricted access to proprietary data create barriers for startups, favoring established firms with deep financial resources and strategic partnerships.
Will synthetic data replace real data?
Synthetic data is increasingly used to supplement real data, but it carries risks of model collapse if overused, especially in domains where verification is difficult. Real, verified data remains the gold standard.
Source: ThorstenMeyerAI.com